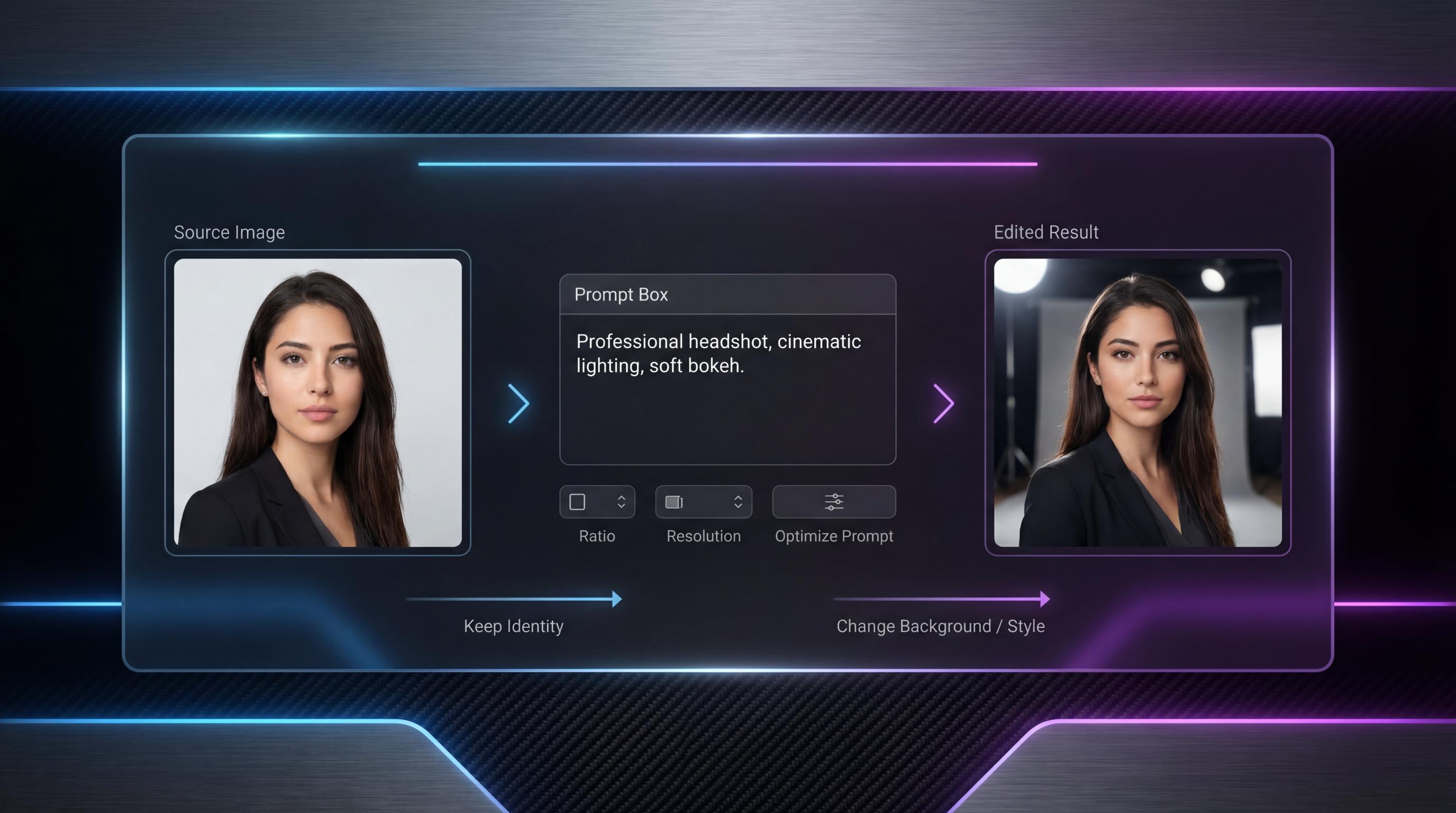
如果你使用过 AI 图像工具超过几分钟,你大概已经意识到一件重要的事:从零生成一张新图很有趣,但在不“弄坏”原图的前提下进行编辑才是真正的考验。
这就是为什么 image-to-image 如此重要。它更贴近真实的创作工作流程。与其指望模型从零猜中你的想法,不如从一张在主体、构图或产品呈现上已经比较到位的底图开始,然后再让模型去改进、换风格或进行局部调整。
同样的,这也是为什么对 Seedream 5.0 AI image-to-image 的分析,比泛泛而谈“这个模型好不好?”更有意义。真正的问题不是第一张出图好不好看,而是:这个工作流程能不能让你以更少摩擦做到一个可用的最终图像。
在本指南中,我们会拆解一套理想的 Seedream 风格 image-to-image 工作流应该具备什么能力,如何正确测试它,它通常在哪些地方翻车,以及为什么像 Sea Imagine AI image-to-image 这样实际可用的替代方案值得一试——前提是你今天就想上手做图。
为什么在真实工作流程中,image-to-image 比 text-to-image 更重要
Text-to-image 非常适合“发散”。当你要探索大致方向、概念与风格时,它很好用。但一旦你开始在乎一致性、可控的版本迭代和精确度,image-to-image 的价值就会显著提高。
原因在于:
- 你可以在多次修改中让主体保持可辨认。
- 你可以保留原有排版/构图,只改某一个元素。
- 你可以把一个好的草稿扩展成一整套可用的变体。
- 你可以把 AI 当作“编辑助手”,而不是“老虎机”。
这种转变对几乎所有真实场景都很关键:
- 角色形象的一致性
- 产品图反复调版
- 背景替换
- 风格迁移
- 社媒创意翻新
- 在不推倒重来的前提下更新营销活动素材
所以当大家讨论 Seedream 5.0 AI image-to-image 时,往往并不是在期待某种魔法特效,而是在寻找一种可以可控修改、不必一次次从头开始的工作流程。
Seedream 5.0 AI 的 image-to-image 理想状态应该做到什么
在理想情况下,一套强大的 Seedream 风格 image-to-image 系统应该在四个方面表现出色。
1)保持身份稳定
如果你上传的是人像,脸应该仍然一眼能认出来;如果上传的是产品,它的轮廓不能乱变形;如果上传的是已经设计好的场景,构图不应随意塌掉。
2)只改你让它改的东西
如果你的提示词写的是“只更换背景”,那么除非你特别要求,主体的脸、服装、姿势、光线方向都不应该乱变。
3)需要时能保留构图
大量的 image-to-image 本质上是在做“构图保留”。你喜欢当前的取景和机位,只是想要更干净的背景、另一种风格或新的氛围。
4)支持基于提示词的精细优化
好的工作流程应该奖励更好的指令。换句话说,提示词越清晰,出图效果越好,而不是让人觉得写得再细也没区别。
这就是 Seedream 5.0 图像编辑工作流背后的真正承诺:更少的重新生成(reroll),更多可用的修改结果,以及更有信心地相信下一次调整会朝你想要的方向前进。
评估任何 Seedream 5.0 AI image-to-image 工作流时值得关注的核心能力
要公平评价一个工具,不要只问“画得漂不漂亮”。要看它在 image-to-image 最容易翻车的地方表现怎样。
身份/主体保持能力
这是最重要的测试之一。
工具能否保持:
- 相同的脸
- 相同的发型
- 相同的产品形状
- 相同的角色服装
- 相同的整体轮廓
一个模型可以生成一张非常好看的单图,但如果每次你一改提示词角色就变脸,那它作为“编辑工具”依然是不合格的。
局部编辑控制力
大部分挫败感都出现在这里。
最好的系统会让你可以这样说:
- “只替换背景”
- “只改变光线”
- “把手里的物体换掉”
- “把夹克从红色改成黑色”
而不会顺手把整张图重画一遍。
风格迁移与风格一致性
一个强的 AI 图像变换系统应该可以在保持可辨认前提下进行风格重绘,包括:
- 把照片变成插画
- 把写实场景变成编辑风/杂志艺术图
- 转换配色与情绪氛围
- 切换渲染风格的同时保持结构稳定
对提示词的响应能力
听起来简单,但影响巨大。
比如工具是否能真正听懂这样的指令:
保持主体身份与构图不变。仅将背景替换为柔和的影棚渐变背景。不要添加额外物体。
如果答案是“能”,这个系统就有实际价值;如果答案是“看运气”,那工作流程就会变得昂贵且不可预测。
一个简单的 Seedream 5.0 AI image-to-image 测试框架
要得到有用的评价,就要用可重复的测试基准,而不是凭感觉。
第一步:选一张质量较好的基础图
选择一张本身就有值得保留之处的图:
- 干净的人像
- 产品照片
- 时尚大片/街拍
- 角色概念图
第二步:做一次“结构保留型”编辑
示例提示词:
保持主体身份和构图不变。仅将背景替换为干净的浅灰色渐变。不要添加新道具。
第三步:做一次风格迁移编辑
示例提示词:
保持同样的姿势和构图,将画面重绘为精致的编辑风插画,使用柔和墨线质感和低饱和配色。
第四步:做一次背景替换
示例提示词:
保持主体不变。将当前背景替换为夜晚的霓虹城市街道。保留相同取景和构图。
第五步:给结果打分
从四个实用维度去看:
- 指令执行准确度
- 一致性
- 编辑干净度
- 最终可用性
最后一项最重要。你不是在比“理论上哪张更好看”,而是在判断“哪一张更接近你真会拿去发布的结果”。
更适合 image-to-image 的提示词结构
许多 image-to-image 失败的提示词都过于模糊。用户只说了“想改什么”,却没说“什么必须保持不变”。
更强的提示结构通常包含三部分:
1)必须保持不变的部分
示例:
- 保持主体身份不变
- 保留当前构图
- 保持相同机位角度
- 保持产品居中
2)应该更改的部分
示例:
- 将背景更改为极简影棚场景
- 将光线改为柔和的黄金时刻光
- 重绘为水彩插画风格
3)必须避免的内容
示例:
- 不要添加额外文字
- 不要改变姿势
- 不要新增道具
- 不要出现杂乱背景
不佳提示 vs 改进后提示
不佳:
做得更有型一点
改进:
保持主体身份和构图不变。将整体风格改为高端时尚杂志风格,软对比、低饱和米色调。不要添加额外物体或文字。
这类小小的提示词升级,往往会对任何 AI 图像变换工作流产生巨大影响。
值得重点分析的常见 image-to-image 使用场景
角色形象一致性
这是人们使用 image-to-image 的最主要原因之一。
你已经有一张满意的人像或概念图,现在你想在不丢失角色的前提下,替换或调整:
- 服装
- 环境
- 表情气质
- 视觉风格
产品图迭代
在电商和营销领域,image-to-image 的价值尤其突出。
你可以基于同一张产品图去尝试:
- 更干净的背景
- 更佳的光线效果
- 不同季节主题
- 各种广告风格
而不必重新组织一次拍摄。
风格迁移
一张基础图可以变成:
- 插画风
- 电影概念图
- 杂志视觉
- 油画/艺术画风
真正的问题在于:这种变化是可控的,还是完全随机的?
社交 & 营销素材焕新
一张活动主视觉往往不需要推倒重做,只是需要:
- 换背景
- 换季节氛围
- 略微调整美术方向
这就是为什么很多人在看过各种模型介绍之后,会希望有一个真正上手可用的 Sea Imagine AI image editor alternative,而不仅仅停留在理论层面。
image-to-image 通常会在哪些地方翻车
这才是现实。
主体漂移
脸变了,产品形状变了,姿势微妙改变。这是高频多轮修改工作流中最令人抓狂的问题之一。
解决思路: 明确锁定主体身份,并缩小每一步修改范围。
过度编辑
你只想改一个点,结果整张图都被重构了。
解决思路: 把一个大改动拆成两三步小改动。
背景“污染”
更换背景时,模型可能会在边缘处混乱,把主体细节和新背景糊在一起,或者引入多余杂物。
解决思路: 使用更干净的底图,先从“极简背景”开始再逐步丰富。
一次性指令太多
如果你试图在一次生成中同时修改服装、光线、背景和风格,你大幅提高了“漂移”的概率。
解决思路: 分步堆叠修改。
文本质量下降
图中如果有文字,经过多次重绘通常会越来越糊、越来越错。
解决思路: 尽量减少图中的文字;必须加字时,用清晰明确的文字提示;版式与文字建议在后期设计工具中单独处理。
一个实用 image-to-image 工具界面应该包含什么
好用的 image-to-image 工作流不仅取决于模型本身,界面设计同样很关键。
一个真正实用的工具界面应该包含:
- 模型切换
- 清晰的图片上传区域
- 提示词输入框
- 提示词翻译或优化功能
- 长宽比选择
- 分辨率选择
- 公开/私密切换
- 可见的额度/点数使用情况
这也是为什么 Sea Imagine AI 的 image-to-image 生成器 是一个很实际的替代方案:它的界面已经把真实图像变换工作中需要的控制项都摆在台面上——图片上传、提示词输入、翻译/优化选项、比例、分辨率、可见性设置和生成控制等。
与其只在理论层面谈 image-to-image,你可以直接在 Sea Imagine AI 的 image-to-image 生成器 上跑一套真实工作流。
替代方案推荐:用 Sea Imagine AI 做真正可落地的 image-to-image
如果你的目标不是“了解个概念”而是立刻“用起来”,那么 Sea Imagine AI image-to-image 是一个很好的起点。
它当前的 image-to-image 页面基于 Nano Banana Pro 模型,提供:
- 图片上传
- 提示词输入
- 翻译开关
- 提示词优化助手
- 比例设置
- 分辨率选项
- 公开/私密可见性
- 清晰的生成控制
这意味着,读者可以直接从理论迈向动手测试。
而这很重要,因为理解 image-to-image 的最快方式并不是读完五个模型介绍,而是用同一张底图、几条不同的真实提示词跑起来,看这个工具在哪些方面能扛住。
其他值得在结尾顺带推荐的 Sea Imagine AI 工具
当读者理解了 image-to-image,再引导他们了解与之相配合的工具,会更符合真实工作流。
用于快速视觉草稿
当你想先产出一个初版概念,再进入编辑阶段时,可以使用 Sea Imagine AI 的 AI image generator 来生成新图。
用于“文字优先”的图像生成
如果用户想从纯文字构思开始创作全新画面,再用 image-to-image 精修,那么 text-to-image generator 就是自然的下一步。
用于让静态图“动”起来
当某次 image-to-image 的最佳结果可以作为动画起始帧时,image to video AI 可以把它变成一个短视频片段。
用于“脚本优先”的内容生产
当用户想完全跨出静态图,从文本概念直接生成视频时,text to video AI tool 就很合适。
用于访问方式与预算规划
还可以引导读者查看 Sea Imagine AI pricing,了解不同套餐、额度与访问权限,以便在投入工作流前做预算规划。
最终总结
要真正分析 Seedream 5.0 AI image-to-image,关键不在于单张“效果图”有多惊艳,而在于它在以下三个维度是否可靠:
- 一致性
- 可控性
- 编辑稳定性
只要一个工具能做到:保持主体身份不乱漂、听得懂“保留 X,只修改 Y”这种指令,并且让你更轻松地获得可用最终图像,它就算是完成了任务。
而如果你现在就想试一个真正可落地的替代方案,可以直接从 Sea Imagine AI image-to-image 开始;然后再按需要扩展到 AI image generation 做新稿、用 text-to-image 做概念创作,或者在准备把静态图变成动态时,尝试 image to video AI。
当这些工具串联成一条完整工作流时,image-to-image 才真正从“炫酷展示”变成“现实生产力”。


